Кодирование и декодирование информации
За правильное выполненное задание получишь 1 балл . На решение отводится примерно 2 минуты .
Для выполнения задания 5 по информатике необходимо знать:
Кодирование - это перевод информации из одной формы представления в другую.
Декодирование - это обратный процесс кодированию.
Кодирование бывает равномерное и неравномерное ;
- при равномерном кодировании все символы кодируются кодами равной длины; Например : ASCII или Unicode.
- при неравномерном кодировании разные символы могут кодироваться кодами разной длины, это затрудняет декодирование, связанные с появлением неоднозначности кода. Например : Символ А кодируется цифрой 0, Б - последовательностью 01, а В - последовательностью 1. Итак, например, сообщение "011" может быть раскодировано, как AВВ или БВ. При неоднозначность кода информацию можно декодировать по разному.
Для однозначного декодирования код должен удовлетворять условию Фано : никакое кодовое слово не может быть началом другого кодового слова.
Информация и ее кодирование
Различные подходы к определению понятия «информация». Виды информационных процессов. Информационный аспект в деятельности человека
Информация (лат. informatio — разъяснение, изложение, набор сведений) — базовое понятие в информатике, которому нельзя дать строгого определения, а можно только пояснить:
- информация — это новые факты, новые знания;
- информация — это сведения об объектах и явлениях окружающей среды, которые повышают уровень осведомленности человека;
- информация — это сведения об объектах и явлениях окружающей среды, которые уменьшают степень неопределенности знаний об этих объектах или явлениях при принятии определенных решений.
Понятие «информация» является общенаучным, т. е. используется в различных науках: физике, биологии, кибернетике, информатике и др. При этом в каждой науке данное понятие связано с различными системами понятий. Так, в физике информация рассматривается как антиэнтропия (мера упорядоченности и сложности системы). В биологии понятие «информация» связывается с целесообразным поведением живых организмов, а также с исследованиями механизмов наследственности. В кибернетике понятие «информация» связано с процессами управления в сложных системах.
Основными социально значимыми свойствами информации являются:
- полезность;
- доступность (понятность);
- актуальность;
- полнота;
- достоверность;
- адекватность.
В человеческом обществе непрерывно протекают информационные процессы: люди воспринимают информацию из окружающего мира с помощью органов чувств, осмысливают ее и принимают определенные решения, которые, воплощаясь в реальные действия, воздействуют на окружающий мир.
Информационный процесс — это процесс сбора (приема), передачи (обмена), хранения, обработки (преобразования) информации.
Сбор информации — это процесс поиска и отбора необходимых сообщений из разных источников (работа со специальной литературой, справочниками; проведение экспериментов; наблюдения; опрос, анкетирование; поиск в информационно-справочных сетях и системах и т. д.).
Передача информации — это процесс перемещения сообщений от источника к приемнику по каналу передачи. Информация передается в форме сигналов — звуковых, световых, ультразвуковых, электрических, текстовых, графических и др. Каналами передачи могут быть воздушное пространство, электрические и оптоволоконные кабели, отдельные люди, нервные клетки человека и т. д.
Хранение информации — это процесс фиксирования сообщений на материальном носителе. Сейчас для хранения информации используются бумага, деревянные, тканевые, металлические и другие поверхности, кино- и фотопленки, магнитные ленты, магнитные и лазерные диски, флэш-карты и др.
Обработка информации — это процесс получения новых сообщений из имеющихся. Обработка информации является одним из основных способов увеличения ее количества. В результате обработки из сообщения одного вида можно получить сообщения других видов.
Защита информации — это процесс создания условий, которые не допускают случайной потери, повреждения, изменения информации или несанкционированного доступа к ней. Способами защиты информации являются создание ее резервных копий, хранение в защищенном помещении, предоставление пользователям соответствующих прав доступа к информации, шифрование сообщений и др.
Язык как способ представления и передачи информации
В зависимости от способа восприятия знаки делятся на:
- зрительные (буквы и цифры, математические знаки, музыкальные ноты, дорожные знаки и др.);
- слуховые (устная речь, звонки, сирены, гудки и др.);
- осязательные (азбука Брайля для слепых, жесты-касания и др.);
- обонятельные;
- вкусовые.
Для долговременного хранения знаки записывают на носители информации.
Для передачи информации используются знаки в виде сигналов (световые сигналы светофора, звуковой сигнал школьного звонка и т. д.).
По способу связи между формой и значением знаки делятся на:
- иконические — их форма похожа на отображаемый объект (например, значок папки «Мой компьютер» на «Рабочем столе» компьютера);
- символы — связь между их формой и значением устанавливается по общепринятому соглашению (например, буквы, математические символы ∫, ≤, ⊆, ∞; символы химических элементов).
Для представления информации используются знаковые системы, которые называются языками . Основу любого языка составляет алфавит — набор символов, из которых формируется сообщение, и набор правил выполнения операций над символами.
Языки делятся на:
- естественные (разговорные) — русский, английский, немецкий и др.;
- формальные — встречающиеся в специальных областях человеческой деятельности (например, язык алгебры, языки программирования, электрических схем и др.)
Системы счисления также можно рассматривать как формальные языки. Так, десятичная система счисления — это язык, алфавит которого состоит из десяти цифр 0..9, двоичная система счисления — язык, алфавит которого состоит из двух цифр — 0 и 1.
Методы измерения количества информации: вероятностный и алфавитный
Единицей измерения количества информации является бит . 1 бит — это количество информации, содержащейся в сообщении, которое вдвое уменьшает неопределенность знаний о чем-либо.
Связь между количеством возможных событий N и количеством информации I определяется формулой Хартли:
Например, пусть шарик находится в одной из четырех коробок. Таким образом, имеется четыре равновероятных события (N = 4). Тогда по формуле Хартли 4 = 2 I . Отсюда I = 2. То есть сообщение о том, в какой именно коробке находится шарик, содержит 2 бита информации.
Алфавитный подход
При алфавитном подходе к определению количества информации отвлекаются от содержания (смысла) информации и рассматривают ее как последовательность знаков определенной знаковой системы. Набор символов языка (алфавит) можно рассматривать как различные возможные события. Тогда, если считать, что появление символов в сообщении равновероятно, по формуле Хартли можно рассчитать, какое количество информации несет каждый символ:
Например, в русском языке 32 буквы (буква ё обычно не используется), т. е. количество событий будет равно 32. Тогда информационный объем одного символа будет равен:
I = log 2 32 = 5 битов.
Если N не является целой степенью 2, то число log 2 N не является целым числом, и для I надо выполнять округление в большую сторону. При решении задач в таком случае I можно найти как log 2 N", где N′ — ближайшая к N степень двойки — такая, что N′ > N.
Например, в английском языке 26 букв. Информационный объем одного символа можно найти так:
N = 26; N" = 32; I = log 2 N" = log 2 (2 5) = 5 битов.
Если количество символов алфавита равно N, а количество символов в записи сообщения равно М, то информационный объем данного сообщения вычисляется по формуле:
I = M · log 2 N.
Примеры решения задач
Пример 1. Световое табло состоит из лампочек, каждая из которых может находиться в одном из двух состояний («включено» или «выключено»). Какое наименьшее количество лампочек должно находиться на табло, чтобы с его помощью можно было передать 50 различных сигналов?
Решение. С помощью n лампочек, каждая из которых может находиться в одном из двух состояний, можно закодировать 2 n сигналов. 2 5 < 50 < 2 6 , поэтому пяти лампочек недостаточно, а шести хватит.
Ответ: 6.
Пример 2. Метеорологическая станция ведет наблюдения за влажностью воздуха. Результатом одного измерения является целое число от 0 до 100, которое записывается при помощи минимально возможного количества битов. Станция сделала 80 измерений. Определите информационный объем результатов наблюдений.
Решение. В данном случае алфавитом является множество целых чисел от 0 до 100. Всего таких значений 101. Поэтому информационный объем результатов одного измерения I = log 2 101. Это значение не будет целочисленным. Заменим число 101 ближайшей к нему степенью двойки, большей 101. Это число 128 = 27. Принимаем для одного измерения I = log 2 128 = 7 битов. Для 80 измерений общий информационный объем равен:
80 · 7 = 560 битов = 70 байтов.
Ответ: 70 байтов.
Вероятностный подход
Вероятностный подход к измерению количества информации применяют, когда возможные события имеют различные вероятности реализации. В этом случае количество информации определяют по формуле Шеннона:
$I=-∑↙{i=1}↖{N}p_ilog_2p_i$,
где $I$ — количество информации;
$N$ — количество возможных событий;
$p_i$ — вероятность $i$-го события.
Например, пусть при бросании несимметричной четырехгранной пирамидки вероятности отдельных событий будут равны:
$p_1={1}/{2}, p_2={1}/{4}, p_3={1}/{8}, p_4={1}/{8}$.
Тогда количество информации, которое будет получено после реализации одного из них, можно вычислить по формуле Шеннона:
$I=-({1}/{2}·log_2{1}/{2}+{1}/{4}·log_2{1}/{4}+{1}/{8}·log_2{1}/{8}+{1}/{8}·log_2{1}/{8})={14}/{8}$ битов $= 1.75 $бита.
Единицы измерения количества информации
Наименьшей единицей информации является бит (англ. binary digit (bit) — двоичная единица информации).
Бит — это количество информации, необходимое для однозначного определения одного из двух равновероятных событий. Например, один бит информации получает человек, когда он узнает, опаздывает с прибытием нужный ему поезд или нет, был ночью мороз или нет, присутствует на лекции студент Иванов или нет и т. д.
В информатике принято рассматривать последовательности длиной 8 битов. Такая последовательность называется байтом.
Производные единицы измерения количества информации:
1 байт = 8 битов
1 килобайт (Кб) = 1024 байта = 2 10 байтов
1 мегабайт (Мб) = 1024 килобайта = 2 20 байтов
1 гигабайт (Гб) = 1024 мегабайта = 2 30 байтов
1 терабайт (Тб) = 1024 гигабайта = 2 40 байтов
Процесс передачи информации. Виды и свойства источников и приемников информации. Сигнал, кодирование и декодирование, причины искажения информации при передаче
Информация передается в виде сообщений от некоторого источника информации к ее приемнику посредством канала связи между ними.
В качестве источника информации может выступать живое существо или техническое устройство. Источник посылает передаваемое сообщение, которое кодируется в передаваемый сигнал.
Сигнал — это материально-энергетическая форма представления информации. Другими словами, сигнал — это переносчик информации, один или несколько параметров которого, изменяясь, отображают сообщение. Сигналы могут быть аналоговыми (непрерывными) или дискретными (импульсными).
Сигнал посылается по каналу связи. В результате в приемнике появляется принимаемый сигнал, который декодируется и становится принимаемым сообщением.
Передача информации по каналам связи часто сопровождается воздействием помех, вызывающих искажение и потерю информации.
Примеры решения задач
Пример 1. Для кодирования букв А, З, Р, О используются двухразрядные двоичные числа 00, 01, 10, 11 соответственно. Этим способом закодировали слово РОЗА и результат записали шестнадцатеричным кодом. Указать полученное число.
Решение. Запишем последовательность кодов для каждого символа слова РОЗА: 10 11 01 00. Если рассматривать полученную последовательность как двоичное число, то в шестнадцатеричном коде оно будет равно: 1011 0100 2 = В4 16 .
Ответ: В4 16 .
Скорость передачи информации и пропускная способность канала связи
Прием/передача информации может происходить с разной скоростью. Количество информации, передаваемое за единицу времени, есть скорость передачи информации , или скорость информационного потока.
Скорость выражается в битах в секунду (бит/с) и кратных им Кбит/с и Мбит/с, а также в байтах в секунду (байт/с) и кратных им Кбайт/с и Мбайт/с.
Максимальная скорость передачи информации по каналу связи называется пропускной способностью канала.
Примеры решения задач
Пример 1. Скорость передачи данных через ADSL-соединение равна 256000 бит/с. Передача файла через данное соединение заняла 3 мин. Определите размер файла в килобайтах.
Решение. Размер файла можно вычислить, если умножить скорость передачи информации на время передачи. Выразим время в секундах: 3 мин = 3 ⋅ 60 = 180 с. Выразим скорость в килобайтах в секунду: 256000 бит/с = 256000: 8: 1024 Кбайт/с. При вычислении размера файла для упрощения расчетов выделим степени двойки:
Размер файла = (256000: 8: 1024) ⋅ (3 ⋅ 60) = (2 8 ⋅ 10 3: 2 3: 2 10) ⋅ (3 ⋅ 15 ⋅ 2 2) = (2 8 ⋅ 125 ⋅ 2 3: 2 3: 2 10) ⋅ (3 ⋅ 15 ⋅ 2 2) = 125 ⋅ 45 = 5625 Кбайт.
Ответ: 5625 Кбайт.
Представление числовой информации. Сложение и умножение в разных системах счисления
Представление числовой информации с помощью систем счисления
Для представления информации в компьютере используется двоичный код, алфавит которого состоит из двух цифр — 0 и 1. Каждая цифра машинного двоичного кода несет количество информации, равное одному биту.
Система счисления — это система записи чисел с помощью определенного набора цифр.
Система счисления называется позиционной , если одна и та же цифра имеет различное значение, которое определяется ее местом в числе.
Позиционной является десятичная система счисления. Например, в числе 999 цифра «9» в зависимости от позиции означает 9, 90, 900.
Римская система счисления является непозиционной . Например, значение цифры Х в числе ХХІ остается неизменным при вариации ее положения в числе.
Позиция цифры в числе называется разрядом . Разряд числа возрастает справа налево, от младших разрядов к старшим.
Количество различных цифр, употребляемых в позиционной системе счисления, называется ее основанием .
Развернутая форма числа — это запись, которая представляет собой сумму произведений цифр числа на значение позиций.
Например: 8527 = 8 ⋅ 10 3 + 5 ⋅ 10 2 + 2 ⋅ 10 1 + 7 ⋅ 10 0 .
Развернутая форма записи чисел произвольной системы счисления имеет вид
$∑↙{i=n-1}↖{-m}a_iq^i$,
где $X$ — число;
$a$ — цифры численной записи, соответствующие разрядам;
$i$ — индекс;
$m$ — количество разрядов числа дробной части;
$n$ — количество разрядов числа целой части;
$q$ — основание системы счисления.
Например, запишем развернутую форму десятичного числа $327.46$:
$n=3, m=2, q=10.$
$X=∑↙{i=2}↖{-2}a_iq^i=a_2·10^2+a_1·10^1+a_0·10^0+a_{-1}·10^{-1}+a_{-2}·10^{-2}=3·10^2+2·10^1+7·10^0+4·10^{-1}+6·10^{-2}$
Если основание используемой системы счисления больше десяти, то для цифр вводят условное обозначение со скобкой вверху или буквенное обозначение: В — двоичная система, О — восмеричная, Н — шестнадцатиричная.
Например, если в двенадцатеричной системе счисления 10 = А, а 11 = В, то число 7А,5В 12 можно расписать так:
7А,5В 12 = В ⋅ 12 -2 + 5 ⋅ 2 -1 + А ⋅ 12 0 + 7 ⋅ 12 1 .
В шестнадцатеричной системе счисления 16 цифр, обозначаемых 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, A, B, C, D, E, F, что соответствует следующим числам десятеричной системы счисления: 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15. Примеры чисел: 17D,ECH; F12AH.
Перевод чисел в позиционных системах счисления
Перевод чисел из произвольной системы счисления в десятичную
Для перевода числа из любой позиционной системы счисления в десятичную необходимо использовать развернутую форму числа, заменяя, если это необходимо, буквенные обозначения соответствующими цифрами. Например:
1101 2 = 1 ⋅ 2 3 + 1 ⋅ 2 2 + 0 ⋅ 2 1 + 1 ⋅ 2 0 = 13 10 ;
17D,ECH = 12 ⋅ 16 -2 + 14 ⋅ 16 -1 + 13 ⋅ 160 + 7 ⋅ 16 1 + 1 ⋅ 16 2 = 381,921875.
Перевод чисел из десятичной системы счисления в заданную
Для преобразования целого числа десятичной системы счисления в число любой другой системы счисления последовательно выполняют деление нацело на основание системы счисления, пока не получат нуль. Числа, которые возникают как остаток от деления на основание системы, представляют собой последовательную запись разрядов числа в выбранной системе счисления от младшего разряда к старшему. Поэтому для записи самого числа остатки от деления записывают в обратном порядке.
Например, переведем десятичное число 475 в двоичную систему счисления. Для этого будем последовательно выполнять деление нацело на основание новой системы счисления, т. е. на 2:
Читая остатки от деления снизу вверх, получим 111011011.
Проверка:
1 ⋅ 2 8 + 1 ⋅ 2 7 + 1 ⋅ 2 6 + 0 ⋅ 2 5 + 1 ⋅ 2 4 + 1 ⋅ 2 3 + 0 ⋅ 2 2 + 1 ⋅ 2 1 + 1 ⋅ 2 0 = 1 + 2 + 8 + 16 + 64 + 128 + 256 = 475 10 .
Для преобразования десятичных дробей в число любой системы счисления последовательно выполняют умножение на основание системы счисления, пока дробная часть произведения не будет равна нулю. Полученные целые части являются разрядами числа в новой системе, и их необходимо представлять цифрами этой новой системы счисления. Целые части в дальнейшем отбрасываются.
Например, переведем десятичную дробь 0,375 10 в двоичную систему счисления:

Полученный результат — 0,011 2 .
Не каждое число может быть точно выражено в новой системе счисления, поэтому иногда вычисляют только требуемое количество разрядов дробной части.
Перевод чисел из двоичной системы счисления в восьмеричную и шестнадцатеричную и обратно
Для записи восьмеричных чисел используются восемь цифр, т. е. в каждом разряде числа возможны 8 вариантов записи. Каждый разряд восьмеричного числа содержит 3 бита информации (8 = 2 І ; І = 3).
Таким образом, чтобы из восьмеричной системы счисления перевести число в двоичный код, необходимо каждую цифру этого числа представить триадой двоичных символов. Лишние нули в старших разрядах отбрасываются.
Например:
1234,777 8 = 001 010 011 100,111 111 111 2 = 1 010 011 100,111 111 111 2 ;
1234567 8 = 001 010 011 100 101 110 111 2 = 1 010 011 100 101 110 111 2 .
При переводе двоичного числа в восьмеричную систему счисления нужно каждую триаду двоичных цифр заменить восьмеричной цифрой. При этом, если необходимо, число выравнивается путем дописывания нулей перед целой частью или после дробной.
Например:
1100111 2 = 001 100 111 2 = 147 8 ;
11,1001 2 = 011,100 100 2 = 3,44 8 ;
110,0111 2 = 110,011 100 2 = 6,34 8 .
Для записи шестнадцатеричных чисел используются шестнадцать цифр, т. е. для каждого разряда числа возможны 16 вариантов записи. Каждый разряд шестнадцатеричного числа содержит 4 бита информации (16 = 2 І ; І = 4).
Таким образом, для перевода двоичного числа в шестнадцатеричное его нужно разбить на группы по четыре цифры и преобразовать каждую группу в шестнадцатеричную цифру.
Например:
1100111 2 = 0110 0111 2 = 67 16 ;
11,1001 2 = 0011,1001 2 = 3,9 16 ;
110,0111001 2 = 0110,0111 0010 2 = 65,72 16 .
Для перевода шестнадцатеричного числа в двоичный код необходимо каждую цифру этого числа представить четверкой двоичных цифр.
Например:
1234,AB77 16 = 0001 0010 0011 0100,1010 1011 0111 0111 2 = 1 0010 0011 0100,1010 1011 0111 0111 2 ;
CE4567 16 = 1100 1110 0100 0101 0110 0111 2 .
При переводе числа из одной произвольной системы счисления в другую нужно выполнить промежуточное преобразование в десятичное число. При переходе из восьмеричного счисления в шестнадцатеричное и обратно используется вспомогательный двоичный код числа.
Например, переведем троичное число 211 3 в семеричную систему счисления. Для этого сначала преобразуем число 211 3 в десятичное, записав его развернутую форму:
211 3 = 2 ⋅ 3 2 + 1 ⋅ 3 1 + 1 ⋅ 3 0 = 18 + 3 + 1 = 22 10 .
Затем переведем десятичное число 22 10 в семеричную систему счисления делением нацело на основание новой системы счисления, т. е. на 7:
Итак, 211 3 = 31 7 .
Примеры решения задач
Пример 1. В системе счисления с некоторым основанием число 12 записывается в виде 110. Указать это основание.
Решение. Обозначим искомое основание п. По правилу записи чисел в позиционных системах счисления 12 10 = 110 n = 0 ·n 0 + 1 · n 1 + 1 · n 2 . Составим уравнение: n 2 + n = 12 . Найдем натуральный корень уравнения (отрицательный корень не подходит, т. к. основание системы счисления, по определению, натуральное число большее единицы): n = 3 . Проверим полученный ответ: 110 3 = 0· 3 0 + 1 · 3 1 + 1 · 3 2 = 0 + 3 + 9 = 12 .
Ответ: 3.
Пример 2. Указать через запятую в порядке возрастания все основания систем счисления, в которых запись числа 22 оканчивается на 4.
Решение. Последняя цифра в записи числа представляет собой остаток от деления числа на основание системы счисления. 22 - 4 = 18. Найдем делители числа 18. Это числа 2, 3, 6, 9, 18. Числа 2 и 3 не подходят, т. к. в системах счисления с основаниями 2 и 3 нет цифры 4. Значит, искомыми основаниями являются числа 6, 9 и 18. Проверим полученный результат, записав число 22 в указанных системах счисления: 22 10 = 34 6 = 24 9 = 14 18 .
Ответ: 6, 9, 18.
Пример 3. Указать через запятую в порядке возрастания все числа, не превосходящие 25, запись которых в двоичной системе счисления оканчивается на 101. Ответ записать в десятичной системе счисления.
Решение. Для удобства воспользуемся восьмеричной системой счисления. 101 2 = 5 8 . Тогда число х можно представить как x = 5 · 8 0 + a 1 · 8 1 + a 2 · 8 2 + a 3 · 8 3 + ... , где a 1 , a 2 , a 3 , … — цифры восьмеричной системы. Искомые числа не должны превосходить 25, поэтому разложение нужно ограничить двумя первыми слагаемыми (8 2 > 25), т. е. такие числа должны иметь представление x = 5 + a 1 · 8. Поскольку x ≤ 25 , допустимыми значениями a 1 будут 0, 1, 2. Подставив эти значения в выражение для х, получим искомые числа:
a 1 = 0; x = 5 + 0 · 8 = 5;.
a 1 =1; x = 5 + 1 · 8 = 13;.
a 1 = 2; x = 5 + 2 · 8 = 21;.
Выполним проверку:
13 10 = 1101 2 ;
21 10 = 10101 2 .
Ответ: 5, 13, 21.
Арифметические операции в позиционных системах счисления
Правила выполнения арифметических действий над двоичными числами задаются таблицами сложения, вычитания и умножения.
Правило выполнения операции сложения одинаково для всех систем счисления: если сумма складываемых цифр больше или равна основанию системы счисления, то единица переносится в следующий слева разряд. При вычитании, если необходимо, делают заем.
Пример выполнения сложения : сложим двоичные числа 111 и 101, 10101 и 1111:

Пример выполнения вычитания: вычтем двоичные числа 10001 - 101 и 11011 - 1101:

Пример выполнения умножения: умножим двоичные числа 110 и 11, 111 и 101:

Аналогично выполняются арифметические действия в восьмеричной, шестнадцатеричной и других системах счисления. При этом необходимо учитывать, что величина переноса в следующий разряд при сложении и заем из старшего разряда при вычитании определяется величиной основания системы счисления.
Например, выполним сложение восьмеричных чисел 36 8 и 15 8 , а также вычитание шестнадцатеричных чисел 9С 16 и 67 16:

При выполнении арифметических операций над числами, представленными в разных системах счисления, нужно предварительно перевести их в одну и ту же систему.
Представление чисел в компьютере
Формат с фиксированной запятой
В памяти компьютера целые числа хранятся в формате с фиксированной запятой : каждому разряду ячейки памяти соответствует один и тот же разряд числа, «запятая» находится вне разрядной сетки.
Для хранения целых неотрицательных чисел отводится 8 битов памяти. Минимальное число соответствует восьми нулям, хранящимся в восьми битах ячейки памяти, и равно 0. Максимальное число соответствует восьми единицам и равно
1 ⋅ 2 7 + 1 ⋅ 2 6 + 1 ⋅ 2 5 + 1 ⋅ 2 4 + 1 ⋅ 2 3 + 1 ⋅ 2 2 + 1 ⋅ 2 1 + 1 ⋅ 2 0 = 255 10 .
Таким образом, диапазон изменения целых неотрицательных чисел — от 0 до 255.
Для п-разрядного представления диапазон будет составлять от 0 до 2 n - 1.
Для хранения целых чисел со знаком отводится 2 байта памяти (16 битов). Старший разряд отводится под знак числа: если число положительное, то в знаковый разряд записывается 0, если число отрицательное — 1. Такое представление чисел в компьютере называется прямым кодом .
Для представления отрицательных чисел используется дополнительный код . Он позволяет заменить арифметическую операцию вычитания операцией сложения, что существенно упрощает работу процессора и увеличивает его быстродействие. Дополнительный код отрицательного числа А, хранящегося в п ячейках, равен 2 n − |А|.
Алгоритм получения дополнительного кода отрицательного числа:
1. Записать прямой код числа в п двоичных разрядах.
2. Получить обратный код числа . (Обратный код образуется из прямого кода заменой нулей единицами, а единиц — нулями, кроме цифр знакового разряда. Для положительных чисел обратный код совпадает с прямым. Используется как промежуточное звено для получения дополнительного кода.)
3. Прибавить единицу к полученному обратному коду.
Например, получим дополнительный код числа -2014 10 для шестнадцатиразрядного представления:
При алгебраическом сложении двоичных чисел с использованием дополнительного кода положительные слагаемые представляют в прямом коде, а отрицательные — в дополнительном коде. Затем суммируют эти коды, включая знаковые разряды, которые при этом рассматриваются как старшие разряды. При переносе из знакового разряда единицу переноса отбрасывают. В результате получают алгебраическую сумму в прямом коде, если эта сумма положительная, и в дополнительном — если сумма отрицательная.
Например:
1) Найдем разность 13 10 - 12 10 для восьмибитного представления. Представим заданные числа в двоичной системе счисления:
13 10 = 1101 2 и 12 10 = 1100 2 .
Запишем прямой, обратный и дополнительный коды для числа -12 10 и прямой код для числа 13 10 в восьми битах:
Вычитание заменим сложением (для удобства контроля за знаковым разрядом условно отделим его знаком «_»):

Так как произошел перенос из знакового разряда, первую единицу отбрасываем, и в результате получаем 00000001.
2) Найдем разность 8 10 - 13 10 для восьмибитного представления.
Запишем прямой, обратный и дополнительный коды для числа -13 10 и прямой код для числа 8 10 в восьми битах:
Вычитание заменим сложением:
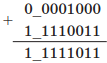
В знаковом разряде стоит единица, а значит, результат получен в дополнительном коде. Перейдем от дополнительного кода к обратному, вычтя единицу:
11111011 - 00000001 = 11111010.
Перейдем от обратного кода к прямому, инвертируя все цифры, за исключением знакового (старшего) разряда: 10000101. Это десятичное число -5 10 .
Так как при п-разрядном представлении отрицательного числа А в дополнительном коде старший разряд выделяется для хранения знака числа, минимальное отрицательное число равно: А = -2 n-1 , а максимальное: |А| = 2 n-1 или А = -2 n-1 - 1.
Определим диапазон чисел, которые могут храниться в оперативной памяти в формате длинных целых чисел со знаком (для хранения таких чисел отводится 32 бита памяти). Минимальное отрицательное число равно
А = -2 31 = -2147483648 10 .
Максимальное положительное число равно
А = 2 31 - 1 = 2147483647 10 .
Достоинствами формата с фиксированной запятой являются простота и наглядность представления чисел, простота алгоритмов реализации арифметических операций. Недостатком является небольшой диапазон представимых чисел, недостаточный для решения большинства прикладных задач.
Формат с плавающей запятой
Вещественные числа хранятся и обрабатываются в компьютере в формате с плавающей запятой , использующем экспоненциальную форму записи чисел.
Число в экспоненциальном формате представляется в таком виде:
где $m$ — мантисса числа (правильная отличная от нуля дробь);
$q$ — основание системы счисления;
$n$ — порядок числа.
Например, десятичное число 2674,381 в экспоненциальной форме запишется так:
2674,381 = 0,2674381 ⋅ 10 4 .
Число в формате с плавающей запятой может занимать в памяти 4 байта (обычная точность ) или 8 байтов (двойная точность ). При записи числа выделяются разряды для хранения знака мантиссы, знака порядка, порядка и мантиссы. Две последние величины определяют диапазон изменения чисел и их точность.
Определим диапазон (порядок) и точность (мантиссу) для формата чисел обычной точности, т. е. четырехбайтных. Из 32 битов 8 выделяется для хранения порядка и его знака и 24 — для хранения мантиссы и ее знака.
Найдем максимальное значение порядка числа. Из 8 разрядов старший разряд используется для хранения знака порядка, остальные 7 — для записи величины порядка. Значит, максимальное значение равно 1111111 2 = 127 10 . Так как числа представляются в двоичной системе счисления, то
$q^n = 2^{127}≈ 1.7 · 10^{38}$.
Аналогично, максимальное значение мантиссы равно
$m = 2^{23} - 1 ≈ 2^{23} = 2^{(10 · 2.3)} ≈ 1000^{2.3} = 10^{(3 · 2.3)} ≈ 10^7$.
Таким образом, диапазон чисел обычной точности составляет $±1.7 · 10^{38}$.
Кодирование текстовой информации. Кодировка ASCII. Основные используемые кодировки кириллицы
Соответствие между набором символов и набором числовых значений называется кодировкой символа. При вводе в компьютер текстовой информации происходит ее двоичное кодирование. Код символа хранится в оперативной памяти компьютера. В процессе вывода символа на экран производится обратная операция — декодирование , т. е. преобразование кода символа в его изображение.
Присвоенный каждому символу конкретный числовой код фиксируется в кодовых таблицах. Одному и тому же символу в разных кодовых таблицах могут соответствовать разные числовые коды. Необходимые перекодировки текста обычно выполняют специальные программы-конверторы, встроенные в большинство приложений.
Как правило, для хранения кода символа используется один байт (восемь битов), поэтому коды символов могут принимать значение от 0 до 255. Такие кодировки называют однобайтными . Они позволяют использовать 256 символов (N = 2 I = 2 8 = 256). Таблица однобайтных кодов символов называется ASCII (American Standard Code for Information Interchange — Американский стандартный код для обмена информацией). Первая часть таблицы ASCII-кодов (от 0 до 127) одинакова для всех IBM-PC совместимых компьютеров и содержит:
- коды управляющих символов;
- коды цифр, арифметических операций, знаков препинания;
- некоторые специальные символы;
- коды больших и маленьких латинских букв.
Вторая часть таблицы (коды от 128 до 255) бывает различной в различных компьютерах. Она содержит коды букв национального алфавита, коды некоторых математических символов, коды символов псевдографики. Для русских букв в настоящее время используется пять различных кодовых таблиц: КОИ-8, СР1251, СР866, Мас, ISO.
В последнее время широкое распространение получил новый международный стандарт Unicode . В нем отводится по два байта (16 битов) для кодирования каждого символа, поэтому с его помощью можно закодировать 65536 различных символов (N = 2 16 = 65536). Коды символов могут принимать значение от 0 до 65535.
Примеры решения задач
Пример. С помощью кодировки Unicode закодирована следующая фраза:
Я хочу поступить в университет!
Оценить информационный объем этой фразы.
Решение. В данной фразе содержится 31 символ (включая пробелы и знак препинания). Поскольку в кодировке Unicode каждому символу отводится 2 байта памяти, для всей фразы понадобится 31 ⋅ 2 = 62 байта или 31 ⋅ 2 ⋅ 8 = 496 битов.
Ответ: 32 байта или 496 битов.
А9 Тема : Кодирование и декодирование информации.
Что нужно знать :
· кодирование – это перевод информации с одного языка на другой (запись в другой системе символов,
в другом алфавите)
· обычно кодированием называют перевод информации с «человеческого» языка на формальный, например, в двоичный код, а декодированием – обратный переход
· один символ исходного сообщения может заменяться одним символом нового кода или несколькими символами, а может быть и наоборот – несколько символов исходного сообщения заменяются одним символом в новом коде (китайские иероглифы обозначают целые слова и понятия)
· кодирование может быть равномерное
и неравномерное
;
при равномерном кодировании все символы кодируются кодами равной длины;
при неравномерном кодировании разные символы могут кодироваться кодами разной длины, это затрудняет декодирование
· закодированное сообщение можно однозначно декодировать с начала , если выполняется условие Фано : никакое кодовое слово не является началом другого кодового слова;
· закодированное сообщение можно однозначно декодировать с конца , если выполняется обратное условие Фано : никакое кодовое слово не является окончанием другого кодового слова;
· условие Фано – это достаточное, но не необходимое условие однозначного декодирования.
Пример задания
По каналу связи передаются сообщения, содержащие только 4 буквы: Е, Н, О, Т. Для кодирования букв Е, Н, О используются 5-битовые кодовые слова: Е - 00000, Н - 00111, О - 11011. Для этого набора кодовых слов выполнено такое свойство: любые два слова из набора отличаются не менее чем в трёх позициях. Это свойство важно для расшифровки сообщений при наличии помех. Какое из перечисленных ниже кодовых слов можно использовать для буквы Т, чтобы указанное свойство выполнялось для всех
четырёх кодовых слов?
1) 1100не подходит ни одно из указанных выше слов
Решение :
1) код, рассмотренный в условии задачи, относится к помехоустойчивым кодам, которые позволяют обнаружить и исправить определенное количество ошибок, вызванных помехами при передаче данных;
1) количество позиций, в которых отличаются два кодовых слова одинаковой длины, называется расстоянием Хэмминга
2) код, в котором расстояние Хэмминга между каждой парой кодовых слов равно d , позволяет обнаружить до d -1 ошибок; для исправления r ошибок требуется выполнение условия
d ≥ 2r + 1
поэтому код с d = 3 позволяет обнаружить одну или две ошибки, и исправить одну ошибку.
3) легко проверить, что для заданного кода (Е - 00000, Н - 00111, О - 11011) расстояние Хэмминга равно 3; в таблице выделены отличающиеся биты, их по три в парах Е-Н и Н-О и четыре
в паре Е-О:
Е – 00000 Е – 00000 Н – 00111
Н – 00111 О – 11011 О – 11011
4) теперь проверяем расстояние между известными кодами и вариантами ответа; для первого ответа 11111 получаем минимальное расстояние 1 (в паре О-Т), этот вариант не подходит:
Т - 11111 Т - 11111 Т - 11111
5) для второго ответа 11100 получаем минимальное расстояние 3 (в парах Е-Т и О-Т):
Е – 00000 Н – 00111 О – 11011
Т - 11100 Т - 11100 Т - 11100
6) для третьего ответа 00011 получаем минимальное расстояние 1 (в паре Н-Т) , этот вариант не подходит:
Е – 00000 Н – 00111 О – 11011
Т - 00011 Т - 00011 Т - 00011
7) таким образом, расстояние Хэмминга, равное 3, сохраняется только для ответа 2 Ответ: 2.
Ещё пример задания:
Для кодирования некоторой последовательности, состоящей из букв А, Б, В, Г и Д, используется неравномерный двоичный код, позволяющий однозначно декодировать полученную двоичную последовательность. Вот этот код: А–00, Б–010, В–011, Г–101, Д–111. Можно ли сократить для одной из букв длину кодового слова так, чтобы код по-прежнему можно было декодировать однозначно? Коды остальных букв меняться не должны. Выберите правильный вариант ответа.
1) для буквы Б –это невозможно
3) для буквы В –для буквы Г – 01
Решение (1 способ, проверка условий Фано) :
8) для однозначного декодирования достаточно, чтобы выполнялось условие Фано или обратное условие Фано;
9) проверяем последовательно варианты 1, 3 и 4; если ни один из них не подойдет, придется выбрать вариант 2 («это невозможно»);
10) проверяем вариант 1: А–00, Б–01, В–011, Г–101, Д–111.
« (код буквы Б совпадает с началом кода буквы В);
«обратное» условие Фано не выполняется (код буквы Б совпадает с окончанием кода буквы Г); поэтому этот вариант не подходит;
11) проверяем вариант 3: А–00, Б–010, В–01, Г–101, Д–111.
«прямое» условие Фано не выполняется (код буквы В совпадает с началом кода буквы Б);
«обратное» условие Фано не выполняется (код буквы В совпадает с окончанием кода буквы Г); поэтому этот вариант не подходит;
12) проверяем вариант 4: А–00, Б–010, В–011, Г–01, Д–111.
«прямое» условие Фано не выполняется
(код буквы Г совпадает с началом кодов букв Б и В);
но «обратное» условие Фано выполняется
(код буквы Г не совпадает с окончанием кодов остальных буквы); поэтому этот вариант подходит;
правильный ответ – 4.
Пример задания: демо_12
Для кодирования некоторой последовательности, состоящей из букв А, Б, В, Г и Д, решили использовать неравномерный двоичный код, позволяющий однозначно декодировать двоичную последовательность, появляющуюся на приёмной стороне канала связи. Использовали код: А–1, Б–000, В–001, Г–011
.
Укажите, каким кодовым словом должна быть закодирована буква Д. Длина этого кодового слова должна быть наименьшей из всех возможных. Код должен удовлетворять свойству однозначного декодирования.
Решение :
13) заметим, что для известной части кода выполняется условие Фано – никакое кодовое слово не является началом другого кодового слова
14) если Д = 00, такая кодовая цепочка совпадает с началом Б = 000 и В = 001 000000: это может быть ДДД или ББ ; поэтому первый вариант не подходит
15) если Д = 01 , такая кодовая цепочка совпадает с началом Г = 011 , невозможно однозначно раскодировать цепочку 011: это может быть ДА или Г ; поэтому второй вариант тоже не подходит
16)
если Д = 11
, условие Фано тоже нарушено: кодовое слово А = 1 совпадает с началом кода буквы Д,
невозможно однозначно раскодировать цепочку 111: это может быть ДА или ААА
; третий вариант
не подходит
17) для четвертого варианта, Д = 010, условие Фано не нарушено; правильный ответ – 4 .
Еще пример задания:
Для передачи по каналу связи сообщения, состоящего только из букв А, Б, В, Г, решили использовать неравномерный по длине код: A=0, Б=10, В=110. Как нужно закодировать
букву Г, чтобы длина кода была минимальной и допускалось однозначное разбиение кодированного сообщения на буквы?
Решение (вариант 1, метод подбора) :
1) рассмотрим все варианты в порядке увеличения длины кода буквы Г
2) начнем с Г=1;
при этом получается, что сообщение «10» может быть раскодировано двояко:
как ГА или Б,
поэтому этот вариант не подходит
3) следующий по длине вариант Г=11
;
в этом случае сообщение «110» может быть раскодировано
как ГА или В,
поэтому этот вариант тоже не подходит 4)третий вариант,
Г=111
, дает однозначное раскодирование во всех сочетаниях букв, поэтому… ответ – 3.
Еще пример задания:
Для кодирования букв А, Б, В, Г решили использовать двухразрядные последовательные двоичные числа (от 00 до 11, соответственно). Если таким способом закодировать последовательность символов БАВГ и записать результат шестнадцатеричным кодом, то получится
Решение :
18) из условия коды букв такие: A – 00, Б –01, В – 10 и Г – 11, код равномерный
19) последовательность БАВГ кодируется так:= 1001011
20) разобьем такую запись на тетрады справа налево и каждую тетраду переведем в шестнадцатеричную систему (то есть, сначала в десятичную, а потом заменим все числа от 10 до 15 на буквы A, B, C, D, E, F); получаем 1001011 = 0 = 4B16 Правильный ответ – 1.
Еще пример задания:
Черно-белое растровое изображение кодируется построчно, начиная с левого верхнего угла и заканчивая в правом нижнем углу. При кодировании 1 обозначает черный цвет, а 0 – белый.
Для компактности результат записали в шестнадцатеричной системе счисления. Выберите правильную запись кода.
1) BD9AA5 2) BDA9B5 3) BDA9D5 4) DB9DAB
Решение :
1) «вытянем» растровое изображение в цепочку: сначала первая (верхняя) строка, потом – вторая, и т. д.:
1 строка | 2 строка | 3 строка | 4 строка |
2) в этой полоске 24 ячейки, черные заполним единицами, а белые – нулями:
1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
||||||||||||||
1 строка | 2 строка | 3 строка | 4 строка |
3) поскольку каждая цифра в шестнадцатеричной системе раскладывается ровно в 4 двоичных цифры, разобьем полоску на тетрады – группы из четырех ячеек (в данном случае все равно, откуда начинать разбивку, поскольку в полоске целое число тетрад – 6):
1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
4)
переводя тетрады в шестнадцатеричную систему, получаем последовательно цифры B (11), D(13), A(10), 9, D(13) и 5, то есть, цепочку BDA9
D5
Правильный ответ – 3.
Еще пример задания:
Для передачи чисел по каналу с помехами используется код проверки четности. Каждая его цифра записывается в двоичном представлении, с добавлением ведущих нулей до длины 4, и к получившейся последовательности дописывается сумма её элементов по модулю 2 (например, если передаём 23 , то получим последовательность 0010 1 00110 ). Определите, какое число передавалось по каналу в виде 0100011 ?
Решение :
1) сначала разберемся, как закодированы числа в примере; очевидно, что используется код равномерной длины; поскольку 2 знака кодируются 10 двоичными разрядами (битами), на каждую цифру отводится 5 бит, то есть 2 → 00101 и 3 → 00110
2) как следует из условия, четыре первых бита в каждой последовательности – это двоичный код цифры, а пятый бит (бит четности) используется для проверки и рассчитывается как «сумма по модулю два», то есть остаток от деления суммы битов на 2; тогда
2 = 00102, бит четности (0 + 0 + 1 + 0) mod 2 = 1
3 = 00112, бит четности (0 + 0 + 1 + 1) mod 2 = 0
3) но бит четности нам совсем не нужен , важно другое: пятый бит в каждой пятерке можно отбросить !
4) разобъем заданную последовательность на группы по 5 бит в каждой:
01010, 10010, 01111, 00011.
5) отбросим пятый (последний) бит в каждой группе: 0101, 1001, 0111, 0001.
это и есть двоичные коды передаваемых чисел: 01012 = 5, 10012 = 9, 01112 = 7, 00012 = 1.
6) таким образом, были переданы числа 5, 9, 7, 1 или число 5971.
7) Ответ: 2.
А9 Задачи для тренировки.
№ 69 – 71
69) По каналу связи передаются сообщения, содержащие только 4 буквы: А, Б, В, Г. Для кодирования букв А, Б, В используются 5-битовые кодовые слова: А - 10000, Б - 00101, В - 01010. Для этого набора кодовых слов выполнено такое свойство: любые два слова из набора отличаются не менее чем в трёх позициях. Это свойство важно для расшифровки сообщений при наличии помех. Какое из перечисленных ниже кодовых слов можно использовать для буквы Г, чтобы указанное свойство выполнялось для всех четырёх кодовых слов?
1) 0110не подходит ни одно из указанных выше слов
70) (http://ege. *****) Для передачи помехоустойчивых сообщений в алфавите, который содержит 16 различных символов, используется равномерный двоичный код. Этот код удовлетворяет следующему свойству: в любом кодовом слове содержится четное количество единиц (возможно, ни одной). Какую наименьшую длину может иметь кодовое слово?
71) По каналу связи передаются сообщения, содержащие только 5 букв А, И, К, О, Т. Для кодирования букв используется неравномерный двоичный код с такими кодовыми словами:
А-0, И-00, К-10, О-110, Т-111.
Среди приведённых ниже слов укажите такое, код которого можно декодировать только одним способом. Если таких слов несколько, укажите первое по алфавиту.
1) КАА 2) ИКОТА 3) КОТ 4) ни одно из сообщений не подходит
1. Для кодирования букв А, Б, В, Г решили использовать двухразрядные последовательные двоичные числа (от 00 до 11 соответственно). Если таким способом закодировать последовательность символов ГБВА и записать результат шестнадцатеричным кодом, то получится:
1) 13DBCA16 3) D
2.
Для 5 букв латинского алфавита заданы их двоичные коды (для некоторых букв - из двух
бит, для некоторых - из трех). Эти коды представлены в таблице:
Определите, какой набор букв закодирован двоичной строкой
1) baade 2) badde 3) bacde 4) bacdb
3.
Для кодирования сообщения, состоящего только из букв A, B, C, D и E, используется
неравномерный по длине двоичный код:
Какое (только одно!) из четырех полученных сообщений было передано без ошибок
и может быть раскодировано:
4. Для передачи по каналу связи сообщения, состоящего только из букв А, Б, В, Г, решили использовать неравномерный по длине код: A=0, Б=100, В=101. Как нужно закодировать букву Г, чтобы длина кода была минимальной и допускалось однозначное разбиение кодированного сообщения на буквы?
5. Черно-белое растровое изображение кодируется построчно, начиная с левого верхнего угла и заканчивая в правом нижнем углу. При кодировании 1 обозначает черный цвет, а 0 – белый.
Для компактности результат записали в восьмеричной системе счисления. Выберите правильную запись кода.1412
6. Для передачи чисел по каналу с помехами используется код проверки четности. Каждая его цифра записывается в двоичном представлении, с добавлением ведущих нулей до длины 4, и к получившейся последовательности дописывается сумма её элементов по модулю 2 (например, если передаём 23, то получим последовательность). Определите, какое число передавалось по каналу в виде?
7.
Для кодирования букв О, Ч, Б, А, К используются двоичные коды чисел 0, 1, 2, 3 и 4 соответственно (с сохранением одного незначащего нуля в случае одноразрядного представления). Если таким способом закодировать последовательность символов
КАБАЧОК и записать результат в шестнадцатеричном коде, то получится:
1) 5434DA4 3) ABCD
8.
Для передачи по каналу связи сообщения, состоящего только из букв А, Б, В, Г, решили использовать неравномерный по длине код: A=01, Б=1, В=001. Как нужно закодировать
букву Г, чтобы длина кода была минимальной и допускалось однозначное разбиение кодированного сообщения на буквы?
9. Для передачи по каналу связи сообщения, состоящего только из букв А, Б, В, Г, решили использовать неравномерный по длине код: A=0, Б=100, В=110. Как нужно закодировать букву Г, чтобы длина кода была минимальной и допускалось однозначное разбиение кодированного сообщения на буквы?
Эксплуатация электронно-вычислительной техники для обработки данных стала важным этапом в процессе совершенствования систем управления и планирования. Но такой метод сбора и обработки информации несколько отличается от привычного, поэтому требует преобразования в систему символов, понятных компьютеру.
Что такое кодирование информации?
Кодирование данных - это обязательный этап в процессе сбора и обработки информации.
Как правило, под кодом подразумевают сочетание знаков, которое соответствует передаваемым данным или некоторым их качественным характеристикам. А кодирование - это процесс составления зашифрованной комбинации в виде списка сокращений или специальных символов, которые полностью передают изначальный смысл послания. Кодирование еще иногда называют шифрованием, но стоит знать, что последняя процедура предполагает защиту данных от взлома и прочтения третьими лицами.
Цель кодирования заключается в представлении сведений в удобном и лаконичном формате для упрощения их передачи и обработки на вычислительных устройствах. Компьютеры оперируют лишь информацией определенной формы, поэтому так важно не забывать об этом во избежание проблем. Принципиальная схема обработки данных включает в себя поиск, сортировку и упорядочивание, а кодирование в ней встречается на этапе ввода сведений в виде кода.
Что такое декодирование информации?
Вопрос о том, что такое кодирование и декодирование, может возникнуть у пользователя ПК по различным причинам, но в любом случае важно донести корректную информацию, которая позволит юзеру успешно продвигаться в потоке информационных технологий дальше. Как вы понимаете, после процесса обработки данных получается выходной код. Если такой фрагмент расшифровать, то образуется исходная информация. То есть декодирование - это процесс, обратный шифрованию.

Если во время кодирования данные приобретают вид символьных сигналов, которые полностью соответствуют передаваемому объекту, то при декодировании из кода изымается передаваемая информация или некоторые ее характеристики.
Получателей закодированных сообщений может быть несколько, но очень важно, чтобы сведения попали в руки именно к ним и не были раскрыты раньше третьими лицами. Поэтому стоит изучить процессы кодирования и декодирования информации. Именно они помогают обмениваться конфиденциальными сведениями между группой собеседников.
Кодирование и декодирование текстовой информации
При нажатии на клавиатурную клавишу компьютер получает сигнал в виде двоичного числа, расшифровку которого можно найти в кодовой таблице - внутреннем представлении знаков в ПК. Стандартом во всем мире считают таблицу ASCII.

Однако мало знать, что такое кодирование и декодирование, необходимо еще понимать, как располагаются данные в компьютере. К примеру, для хранения одного символа двоичного кода электронно-вычислительная машина выделяет 1 байт, то есть 8 бит. Эта ячейка может принимать только два значения: 0 и 1. Получается, что один байт позволяет зашифровать 256 разных символов, ведь именно такое количество комбинаций можно составить. Эти сочетания и являются ключевой частью таблицы ASCII. К примеру, буква S кодируется как 01010011. Когда вы нажимаете ее на клавиатуре, происходит кодирование и декодирование данных, и мы получаем ожидаемый результат на экране.
Половина таблицы стандартов ASCII содержит коды цифр, управляющих символов и латинских букв. Другая ее часть заполняется национальными знаками, псевдографическими знаками и символами, которые не имеют отношения к математике. Совершенно ясно, что в различных странах эта часть таблицы будет отличаться. Цифры при вводе также преобразовываются в двоичную систему вычисления согласно стандартной сводке.

Кодирование чисел
Подобный метод кодирования точек изображений применяется и в полиграфической отрасли. Только здесь принято задействовать четвертый цвет - черный. По этой причине полиграфическую систему преобразования обозначают аббревиатурой CMYK. Эта система для представления изображений использует целых тридцать два двоичных разряда.

Способы кодирования и декодирования информации предполагают использование различных технологий, в зависимости от типа вводимых данных. К примеру, графических изображений шестнадцатиразрядными двоичными кодами называется High Color. Эта технология дает возможность передавать на экран целых двести пятьдесят шесть оттенков. Уменьшая количество задействованных двоичных разрядов, применяемых для шифрования точек графического изображения, вы автоматически уменьшаете объем, необходимый для временного хранения информации. Такой метод кодирования данных принято называть индексным.
Кодирование звуковой информации
Теперь, когда мы рассмотрели, что такое кодирование и декодирование, и методы, лежащие в основе этого процесса, стоит остановиться на таком вопросе, как кодирование звуковых данных.
Звуковую информацию можно представить в виде элементарных единиц и пауз между каждой их парой. Каждый сигнал преобразовывается и сохраняется в памяти компьютера. Звуки выводятся с помощью который используется хранящиеся в памяти ПК зашифрованные комбинации.
Что касается человеческой речи, то ее гораздо сложнее закодировать, ведь она отличается многообразием оттенков, и компьютеру приходится сравнивать каждое словосочетание с эталоном, предварительно занесенным в его память. Распознавание произойдет лишь в случае, когда сказанное слово будет найдено в словаре.
Кодирование информации в двоичном коде
Существуют различные методики реализации такой процедуры, как кодирование числовой, текстовой и графической информации. Декодирование данных обычно происходит по обратной технологии.
При кодировании чисел даже учитывается цель, с которой цифра была введена в систему: для арифметических вычислений или просто для вывода. Все данные, кодируемые в двоичной системе, шифруются с помощью единиц и ноликов. Эти символы еще называют битами. Этот метод кодировки является наиболее популярным, ведь его легче всего организовать в технологическом плане: присутствие сигнала - 1, отсутствие - 0. У двоичного шифрования есть лишь один недостаток - это длина комбинаций из символов. Но с технической точки зрения легче орудовать кучей простых, однотипных компонентов, чем малым числом более сложных.
Преимущества двоичного кодирования
- Такая форма представления информации подходит для различных ее видов.
- При передаче данных не возникает никаких ошибок.
- ПК намного легче обрабатывать данные, закодированные таким способом.
- Требуются устройства с двумя состояниями.
Недостатки двоичного кодирования
- Большая длина кодов, которая несколько замедляет их обработку.
- Сложность восприятия двоичных комбинаций человеком без специального образования или подготовки.

Заключение
Ознакомившись с этой статьей, вы смогли узнать, что такое кодирование и декодирование и для чего его используют. Можно сделать вывод, что используемые методики преобразования данных полностью зависят от типа информации. Это может быть не только текст, а еще и числа, изображения и звук.
Кодирование различной информации позволяет унифицировать форму ее представления, то есть сделать однотипной, что значительно ускоряет процессы обработки и автоматизации данных при дальнейшем использовании.
В электронно-вычислительных машинах чаще всего используют принципы стандартного двоичного кодирования, которое исходную форму представления информации преобразовывает в формат, более удобный для хранения и дальнейшей обработки. При декодировании все процессы происходят в обратном порядке.
Но голосом ведь всем её не донесёшь. Поэтому с давних времён был важен момент кодирования данных, чтобы они могли был прочитаны теми, для кого предназначалось. Постепенно также стало актуальным их шифрование. Необходимо было поместить в сообщение информацию, которая была понятна своим и не раскрыла смысла перед чужими. Обо всём этом мы и поговорим, выясняя, что такое кодирование и декодирование.
Разбираемся с терминологией
Без этого никак. Когда говорят о закодированном тексте, то это значит, что ему был сопоставлен другой набор символов. Это может быть использовано для увеличения надежности или же по той простой причине, что канал может использовать только ограниченное количество символом. Например, двоичный код, на котором работают современные компьютеры, построен на нулях и единицах.
Информация может быть закодирована в определённые символы и для того, чтобы её сохранить. В качестве примера можно привести результаты анализов, где содержатся показатели организма человека. Но наиболее популярным вопросом является такой: "Что такое кодирование и декодирование в информатике?" Искать ответ на него мы и будем.
О значении
Ранее процесс кодирования и декодирования информации играл вспомогательную роль и не рассматривался как отдельное направление математики. Но с появлением электронно-вычислительных машин ситуация существенно изменилась. Сейчас кодирование является центральным вопросом во время решения широкого спектра практических задач в программировании и поэтому пронизывает все информационные технологии. Так, с его помощью:
- Защищается информация от несанкционированного доступа.
- Обеспечивается помехоустойчивость при передаче по каналам связи данных.
- Представляется информация произвольной природы (графика, текст, числа) в памяти компьютера.
- Сжимается содержимое баз данных.
Об алфавите

Говоря о том, что такое кодирование и декодирование, сложно обойти вниманием основу всего этого. А именно, алфавит. Выделяют два вида - исходный и кодовый. В первом имеется начальная информация. Под кодовым подразумеваются изменённые данные, которые тем не менее могут при наличии ключа передать нам зашифрованное содержимое. В информатике для этого используется двоичный код, в основу которого положен алфавит, состоящий из нуля и единицы.
Давайте рассмотрим небольшой пример. Допустим, у нас есть два алфавита (А и Б), что состоят из конечного числа символов. Допустим, они выглядят следующим образом: А = {А0, А1, А2….А33}, Б = {Б0, Б1, Б3…Б34}. Элементы алфавита - это буквы. Тогда как их упорядоченный набор называется словом. У него есть определённая длина. Первая буква слова называется началом (префиксом), тогда как последняя - окончанием (постфиксом). Могут существовать различные правила построения конструкций. Например, одни системы кодирования информации требуют, чтобы был пропуск между словами, вторые обходятся без него. В целом алфавит необходим для построения универсальной системы отображения информации, её хранения, обработки и передачи. При этом предусматривается определённое соответствие между различными сигналами и элементами сообщений, которые в них зашифрованы.
Работа с данными

Когда информация преобразовывается в первоначальный вид, то происходящий при этом процесс называется декодирующим. Он должен выполняться по отношению к любым данным, что были зашифрованы. При этом используется так называемое обратное отображение (биекция). Давайте рассмотрим ситуацию с двоичной системой. У неё все кодовые слова обладают одинаковой длиной. Поэтому код называют равномерным (блочным). При этом кодирующей функцией выступает определённая подстановка. Можно взять в качестве примера вышеприведенную систему алфавита. Для обозначения определённых последовательностей используется множество элементарных кодов.
Допустим, что у нас есть А0 = {А, Б, В, Г} и Б0 = {1, 0}. Каким образом это можно представить компьютеру? А используя вот такую последовательность: А = 00, Б = 01, В = 10, Г = 11. Как видите, каждый символ имеет определённую кодировку. В компьютерную технику заносится справочная информация про алфавит кодирования, и она начинает ждать поступающих сигналов. Приходит нуль, за ним ещё один - ага, значит, это буква А. Если проводить параллели с набором слова в текстовом редакторе, то следует отметить, что будет передана не только одна буква, но и запущена соответствующая реакция на неё. Например, загорится определённая последовательность светодиодов монитора, где отображаются все введённые символы.
Специфика работы

Говоря про примеры кодирования и декодирования информации, следует отметить, что рассматриваемая система не является взаимно-однозначной. Например, букве А может соответствовать комбинация не только 00, но и 11, 10 или 01. Но при этом следует учитывать, что может быть только что-то одно. То есть за комбинацией закрепляется исключительно только определённый символ. Если схема кодирования подразумевает разделение любого слова на элементарные составляющие, то она называется разделимой. В случаях, когда одна буква не выступает в качестве начала другой, это префиксный подход. Это относится к вопросам программно-аппаратной составляющей. Определённое влияние на кодирование оказывает и архитектура, но из-за большого количества вариантов реализации рассматривать её довольно проблематично.
Побуквенное кодирование
Это наиболее простой подход. Если говорить про языки кодирования информации, то, пожалуй, это наиболее популярный вариант. В ограниченном варианте он был рассмотрен выше. Давайте узнаем, как выглядит код без разделителей. Допустим, у нас есть алфавит (исходный), в который помещены все русские буквы. Для кодирования используются десятичные цифры. Здесь А = 1, а Я = 33. Таким образом, последовательность букв АЯЯА можно передать как 133331. Если есть желание сделать алфавит равномерным, то необходимо внести определённые изменения. Так, для первых девяти букв придётся добавить по нулю. И рассмотренный нами пример АЯЯА превращается в 01333301.
Неравномерное кодирование
Рассмотренный ранее вариант считается удобным. Но в определённых случаях более умно сделать ставку на неравномерные коды. Это имеет смысл тогда, когда разные буквы в исходном тексте встречаются с различной частотой. Поэтому более частые символы имеет смысл кодировать короткими обозначениями, а редкие - длинными. Давайте построим бинарное дерево из букв русского алфавита. А на дополнение возьмём спецсимволы. Наиболее часто используются буквы, поэтому начинать мы будем с них: А - 0, Б - 1, В - 10, Г - 11 и так далее. И только после них уже будут использоваться знаки вопроса, процентов, двоеточия и прочие. Хотя, пожалуй, на первое место всё же следует поставить запятые и точки.
Об условии Фано

Теорема гласит, что любой код (префиксный и равномерный) допускает возможность однозначного кодирования. Допустим, что мы используем рассмотренный ранее пример с 01333301. Начинаем двигаться вправо. 0 ничего нам не даёт. А вот 01 позволяет идентифицировать букву А. Немного изменим начальный код и представим его как 01 333301. Далее выделяем первую Я, вторую и ещё одну А. В результате мы имеем 01 33 33 01. Хотя первоначально код был слитным, но сейчас мы можем с легкостью его декодировать, поскольку знаем, что в нём есть. А именно - А Я Я А. При этом заметьте, что он всегда расшифровывается однозначно, и никаких толкований в рамках принятой системы нет, благодаря чему можно обеспечить высокую достоверность передаваемой информации. Но как работают компьютеры?
Функционирование электронно-вычислительных машин
Кодирование и декодирование сигналов компьютерной техники базируется на использовании так называемых низких и высоких сигналов, которым в логическом измерении соответствуют нуль и единица. Что это значит? Допустим, у нас есть микроконтроллер. Если на один его вход поступает низкое напряжение в 1,5 В, то считается, что было передано значение логического нуля. Но если будет передано 5 В, то в соответствующую ячейку памяти будет записана единица. При этом необходимо добиться согласования источника информации с каналом связи. Вообще, при создании электроники необходимо учитывать большое количество различных моментов. Это и энергетические требования, и вид передаваемой информации (дискретная или непрерывная), и многое другое. При этом данные постоянно должны преобразовываться таким образом, чтобы они могли передаваться по каналам связи. Так, в случае с двоичной техникой сигналы представлены в виде напряжения, подаваемого на вход транзисторов или иных компонентов. Во время декодирования данные переводят сообщение в понятный для получателя вид.
Минимальная избыточность

На практике оказалось, что чрезвычайно важным является, чтобы код сообщения имел минимальную длину. Первоначально может показаться, какая разница - шесть, восемь или шестнадцать бит используется для кодирования? Но различия несущественны, если используется одно слово. А если миллиарды? Благо, можно подстроить алфавитное кодирование под все выдвигаемые требования. Но если про множество ничего неизвестно, то в таком случае сформулировать задачу оптимизации довольно трудно. Но на практике, как правило, всё же можно получить дополнительную информацию. Рассмотрим небольшой пример. Допустим, у нас есть сообщение, представленное на естественном языке. Но оно закодировано, и мы не можем прочитать его. Что нам поможет в задаче расшифровки? Как один из возможных вариантов - листок бумаги, на котором распределена вероятность появления букв. Благодаря этому построение оптимального кода в плане де/кодирования становится возможным с использованием точной математической формулировки и строгого решения.
Разбираем пример
Допустим, что у нас есть определённая разделимая схема алфавитного кодирования. Тогда все производные, что представляют собой упорядоченный набор, тоже будет иметь это свойство. При этом если длина элементарных кодов равна, то их перестановка не влияет на длину всего сообщения. Но если размер передаваемой информации напрямую зависит от того, какая последовательность букв, то, значит, были использованы составляющие различной протяженности. При этом, если есть конкретное сообщение и схема его кодирования, то можно подобрать такое решение задачи, когда его длина будет минимальной. Как этого достичь? Давайте рассмотрим подход с использованием алгоритма назначения элементарных кодов, позволяющего результативно подойти к решению задачи эффективности:
- Следует отсортировать буквы в порядке убывания количественного вхождения.
- Нужно разместить элементарные коды в порядке увеличения их длины.
- И как завершение, необходимо разместить составляющие в оптимальном порядке, чтобы наиболее частые символы занимали меньше всего места.
В целом система несложная. Если работать с небольшими объемами данных. Но с современными компьютерами такое реализовать довольно проблематично из-за значительного количества информации.
Заключение

Вот мы и рассмотрели, что такое система кодирования и декодирования информации, какой она может быть, что сейчас существует в информатике, а также множество иных вопросов. Но всё же следует понимать, что эта тема является чрезвычайно объемной, одной статьи для этого недостаточно. Как продолжение темы можно рассмотреть шифрование данных, криптографию, изменение отображения информации в различной электронике, уровни её обработки и множество других моментов. Но отрасль компьютерных наук по праву считается одной из самых сложных, поэтому изучить всё это быстро не получится. К тому же теоретические знания здесь ой как не равны практическим умениям. А именно последние и обеспечивают качественный результат.



